Calculate PCA for spectra
While superimposing spectra allows you to check differences between 2 or 3 experiments, it becomes tedious to compare a large set of data.
Many data mining algorithms may help in those cases and here we propose to analyze the data using principal component analysis.
Principal component analysis (PCA) is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables (here spectra) into a set of values of linearly uncorrelated variables called principal components. If there are n observations with p variables, then the number of distinct principal components is min(n-1,p). This transformation is defined in such a way that the first principal component has the largest possible variance (that is, accounts for as much of the variability in the data as possible), and each succeeding component in turn has the highest variance possible under the constraint that it is orthogonal to the preceding components. The resulting vectors (each being a linear combination of the variables and containing n observations) are an uncorrelated orthogonal basis set. PCA is sensitive to the relative scaling of the original variables.
The workflow is the following:
- Select samples and add spectra
- Preprocess the spectra using various parameters
- Calculate the PCA
- Display each spectrum in the new space
Spectra selection, normalization and previsualization
The first step is to select the spectra :
How to select spectra.
Spectra selection
All the spectra analysis tools start with a phase of selection.
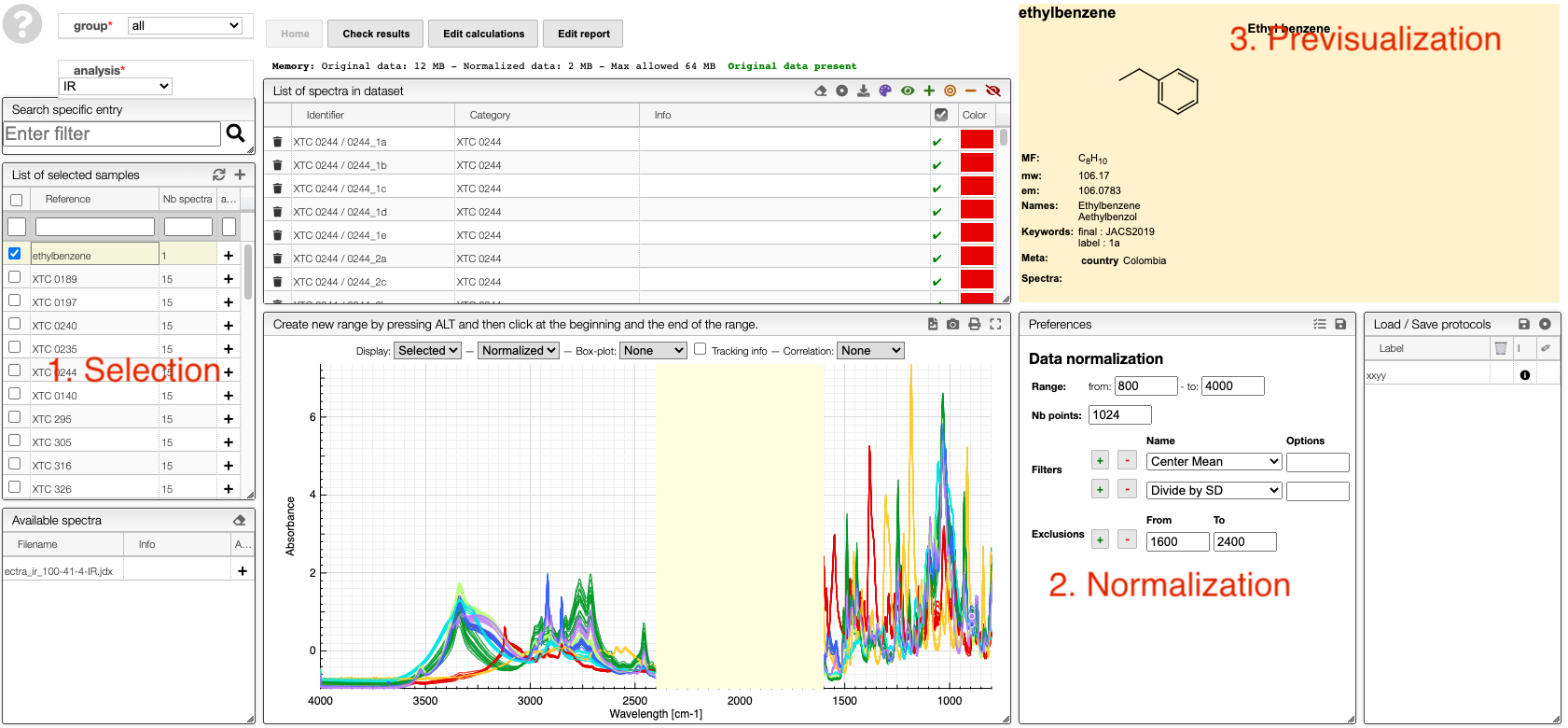
Select samples
In order to facilitate the analysis of the spectra it is advised to have samples containing representative spectra in order to evaluate the intra-variability as well as the reproducibility.
Selection of spectra to analyze is achieved with one of those 3 methods:
At the level of the sample by either clicking on the +, this will add all the spectra related to this sample or on the + on the top of the sample box to add all the spectra of all the selected samples.
If you select a sample it is also possible to add a specific spectrum by clicking on the + at the level of the spectra list.
Once spectra have been selected, data normalization filters can be applied :
Apply mathematical tools to the spectra.
Preprocessing
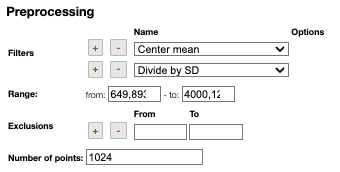
Filters
You can apply the following filters to the spectra to enhance the visualization. The modifications include the following:
Center Mean: subtract the mean from every variable observation in the dataset, so that the new variable's mean is centered at 0.Center Median: subtract the median from every variable observation in the dataset, so that the new variable's median is centered at 0`Divide by SD: divide every variable observable in the dataset by the standard deviation yields a distribution with a standard deviation equal to 1.Normed: Specify a value in thevaluefield and select the type of normalization:Sum to value: normalize the integral under the curve so that it sums to the specified value.Absolute sum to value: normalize the integral under the curve so that the absolute sum sums to the specified value.Max to value: normalize the maximum value to the specified value.
Rescale (x to y): rescale the graph such that the y-values fit between specified minimum and maximum values.First derivative: calculate the first derivative of the spectra.Second derivative: calculate the second derivative of the spectra.Third derivative: calculate the third derivative of the spectra.Savitzky-Golay: smooth the spectra and calculate derivatives based on the following parameters:Window: smoothing window size, must be an odd number, greater than 5.Derivative: derivative order.Polynomial: the degree of the polynomial used to calculate the Savitzky-Golay.
AirPLS baseline: baseline correction using adaptive iterative reweighed penalized least squares algorithm.Iterative polynomial baseline: baseline correction using iterative polynomial fitting algorithm.Rolling average baseline: baseline correction using a rolling average.Rolling median baseline: baseline correction using a rolling median.Rolling ball baseline: baseline correction using a rolling ball.Ensure growing X values: ensure that the x-values are in increasing order.Function on X: apply a function to the x-values. For example,log(x).Function on Y: apply a function to the y-values. For example,log10(y+1).Calibrate X: calibrate the x-values with the parametersfrom,to,nbPeakandtargetX.Pareto normalization: Pareto scaling, which uses the square root of standard deviation as the scaling factor, circumvents the amplification of noise by retaining a small portion of magnitude information. 10.1016/j.molstruc.2007.12.026
One classical preprocessing algorithm is Standard Normal Variate (SNV). This preprocessing can be achieved by selecting the 2 options Center mean and Divide by SD.
Selecting the range
A certain range of x-values can be selected to show only a part of the spectrum using Range.
Exclusions
Depending on the analysis, some regions should be removed using Exclusions in order to improve the visualization.
Number of points
Number of points can be changed to reduce the number of points in the spectra.
The superimposed spectra can be manipulated using numerous options:
How to visualize spectra.
Spectra visualization
Numerous options are available to display either all the spectra in the dataset or only the selected spectra.
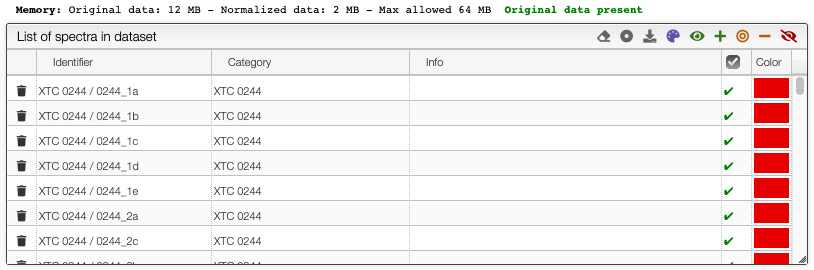
Selection of spectra in the dataset
The toolbar on the top of the list of spectra in the dataset provides many options (from left to right):
![]()
- Remove all spectra from dataset
- Select category: select which property contains the category description
- Download normalized matrix
- Recolor spectra based on category: a different color will be applied for each category. By default, the sample reference
- Select all spectra
- Append to selected spectra
- Select only current spectra
- Remove spectra from current selection
- Unselect all spectra
Graph options
It is possible to either display the selected spectra, all the spectra or various derived information.
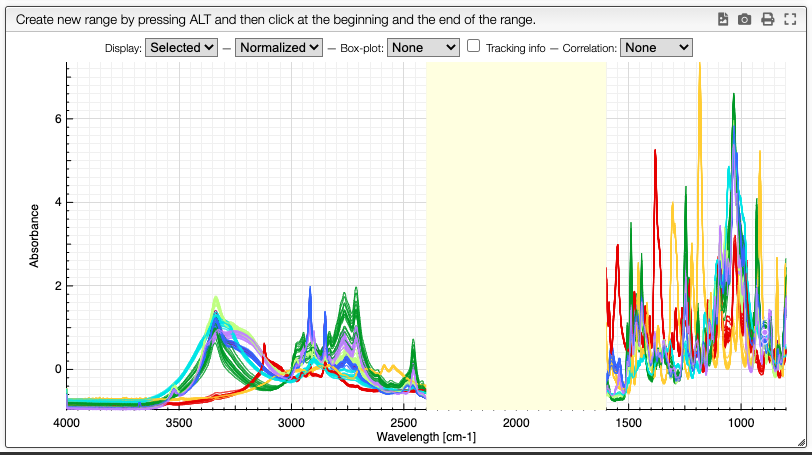
Customization of the display is achieved using the chart toolbar:
![]()
Display spectra
The first options allow you to display all the spectra, only the selected spectra, or nothing.
Displaying no spectrum is useful when displaying other derived data.
Original / normalized
These options allow you to display either the original spectra or the normalized data. Most of the time we will display normalized data. These are the data that will be analyzed, and they also typically take less memory.

Boxplot
The boxplot kind of representation allows to display the first / third quartile as a dark grey zone for each X point. The min and max values are represented as a light gray zone and the median is represented as a line for which the color varies based on the standard deviation (red: high variation, blue: small variation).
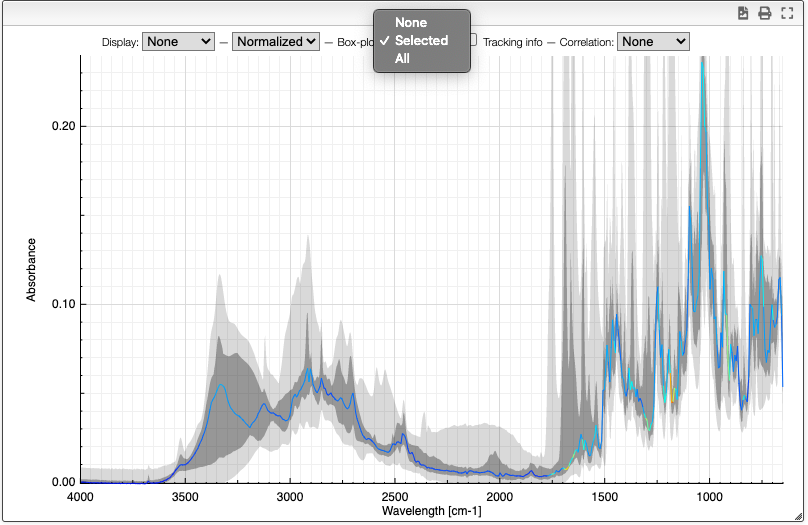
Tracking information
By selecting the tracking information you will display the X values and the corresponding Y values for all the spectra.
![]()
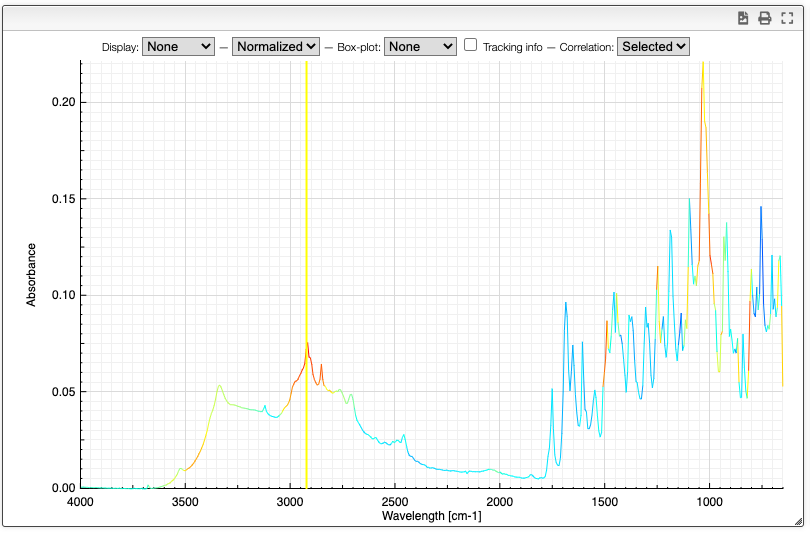
Correlation
Correlation of the vector represented by the Y points can be useful to determine which peaks are correlated in a big mixture of products. This is known in NMR metabolomics as STOCSY.
By SHIFT ⇧ + ALT + click you can select the X value for which you would like to check correlation. Strongly correlated signals will appear in red while non correlated signals are blue.
Create the PCA model
In order to generate the PCA model you should click on the Recalculate PCA button that can be found in the PCA tab.
Even after creating the model, you may still add new spectra. Those spectra will be projected into the new PCA space. The spectra used for the calculations are represented with a filled circle, while those projected are represented with an open circle.
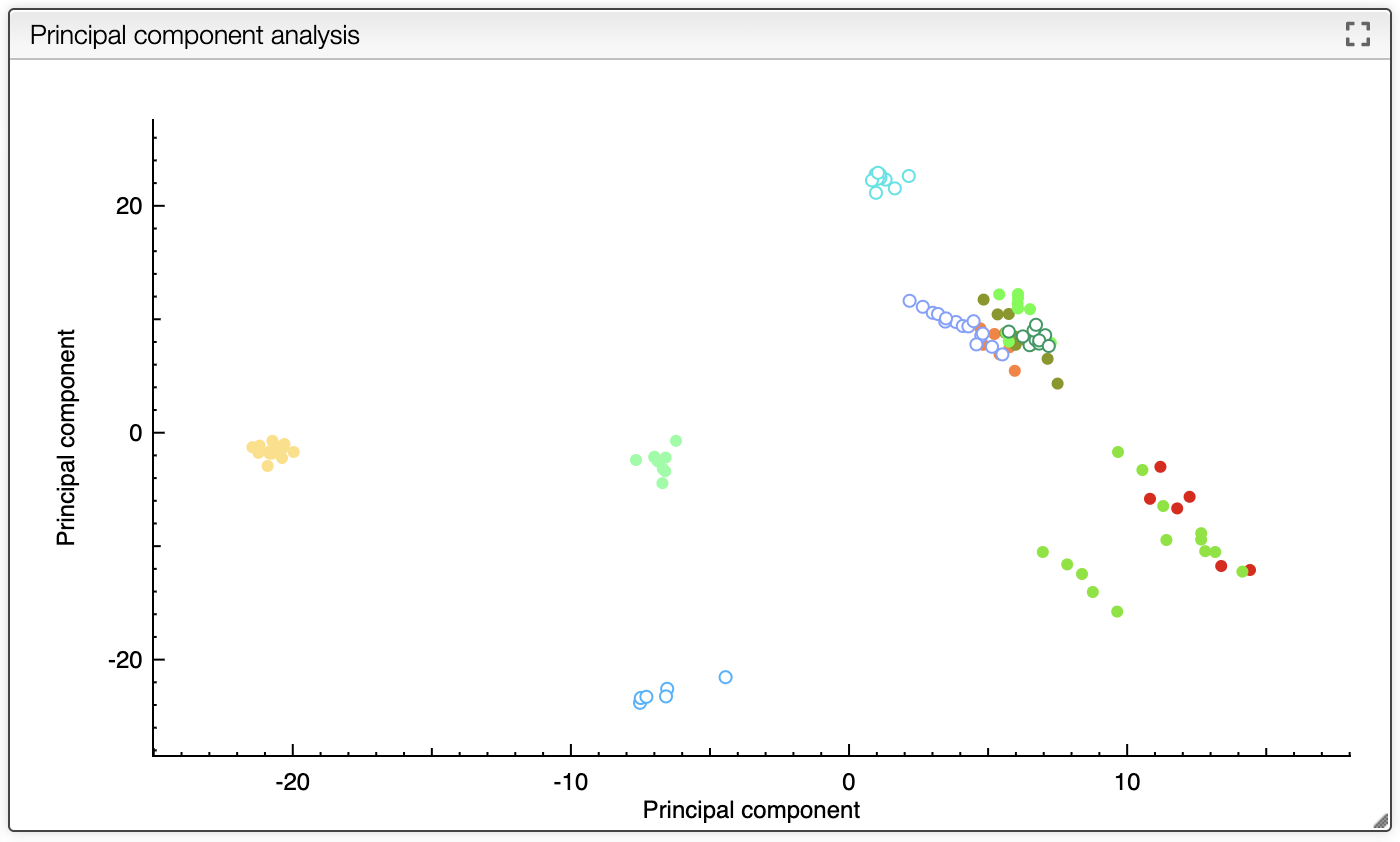
By default, each sample will have a different color.
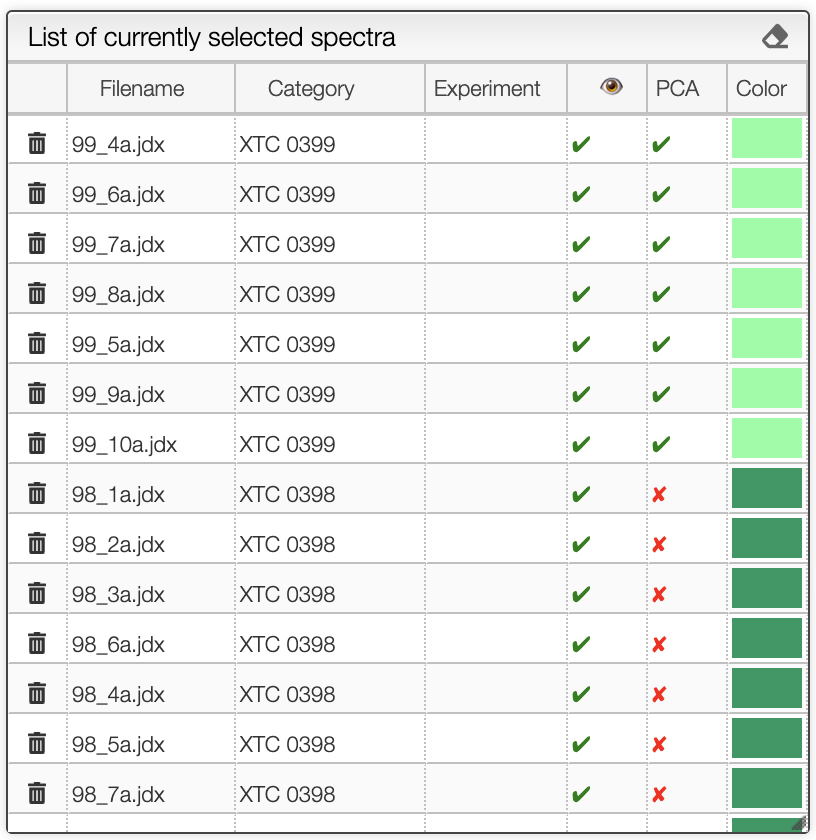
In the list of selected samples, you can check which spectra are used for the PCA calculation and which ones are merely projected onto the model.
Advanced analysis
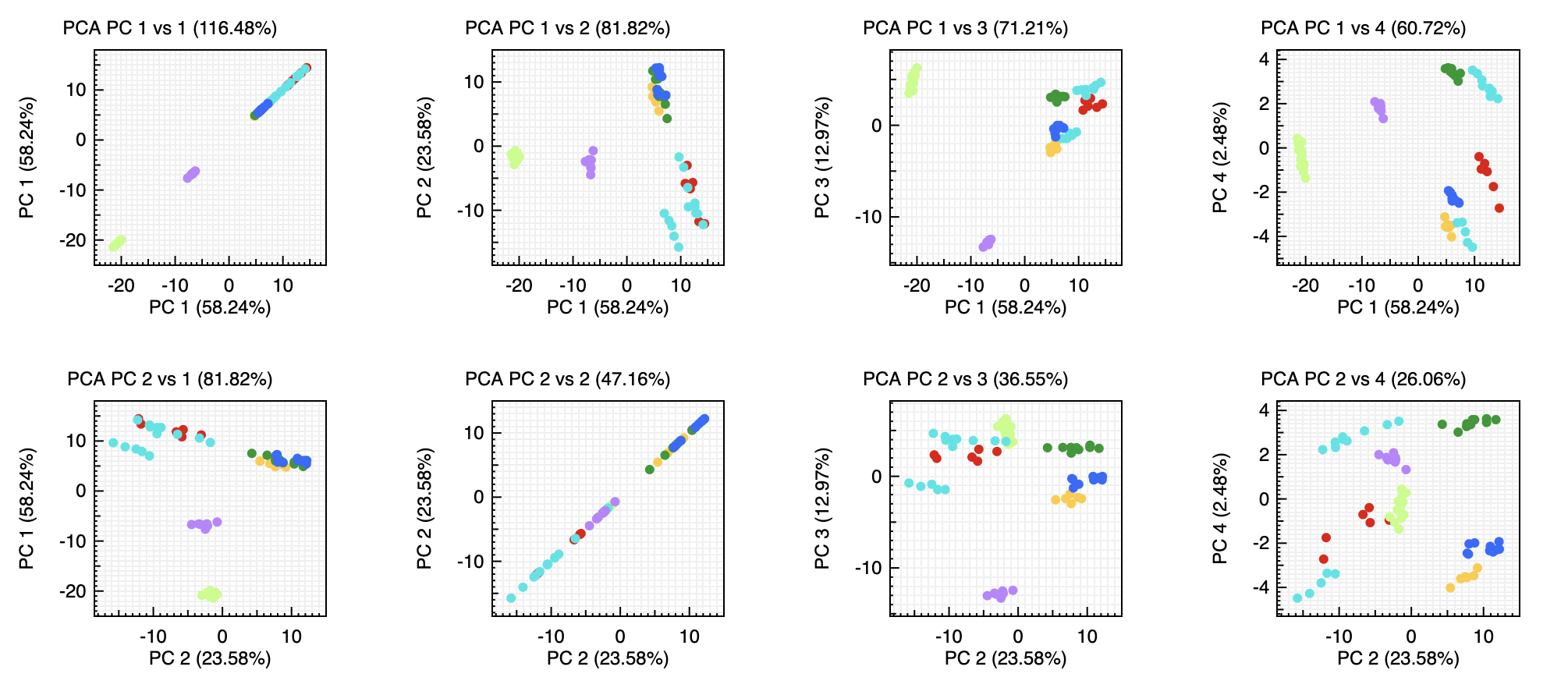
By selecting PCA PC you can check the various principal component as well as the explained variance.
While PC1 versus PC2 offers usually a good separation it is not always the best that can be achieved and in this view we plot the 4 first principal components against each other.
In this specific example we can see that the best separation is obtained when using PC2 versus PC3.